Data-driven prescribing






Computational psychiatry is an emerging field in which artificial intelligence and machine learning are used to find hidden patterns in big data to better understand, predict, and treat mental illness. The field uses various mathematical models to predict the dependent variable y based on the independent variable x. One application of analytics in medicine was the Framingham Heart Study, which used multivariate logistic regression to predict heart disease.1
Analytics could be used to predict the number of bad outcomes associated with different psychiatric medications over time. To demonstrate this, I examined a select data set of 8 psychiatric medications (aripiprazole, ziprasidone, risperidone, olanzapine, sertraline, trazodone, amitriptyline, and lithium) accounting for 59,827 bad outcomes during a 15-year period as reported by U.S. poison control centers,2 and plotted these on the y-axis.
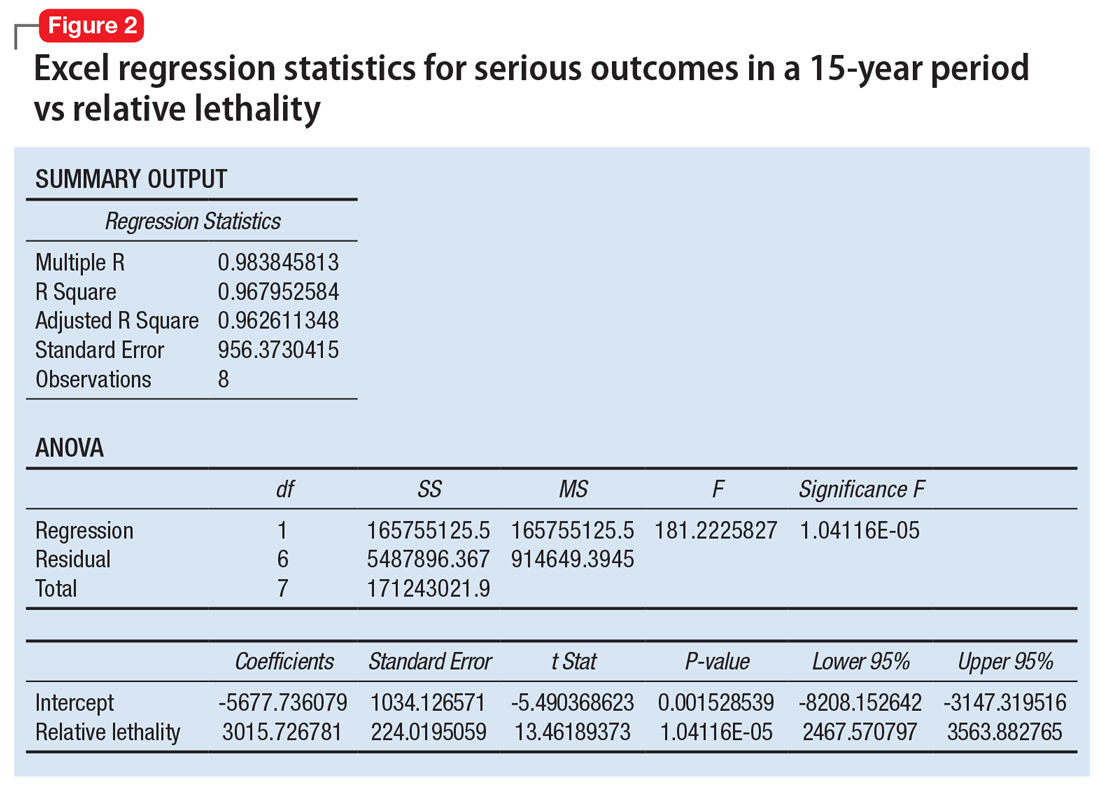
When considering the independent variable to use as a predictor for bad outcomes, I used a composite index derived with the relative lethality (RL) equation, f(x) = 310x /LD50, where x is the daily dose of a medication prescribed for 30 days, and LD50 is the rat oral lethal dose 50.3 I plotted the RL of the 8 medications on the x-axis. Then I attempted to find a mathematical function that would best fit the x and y intersection points (Figure 1). I used the Excel data analysis pack to run a logarithmic regression model (Figure 2).
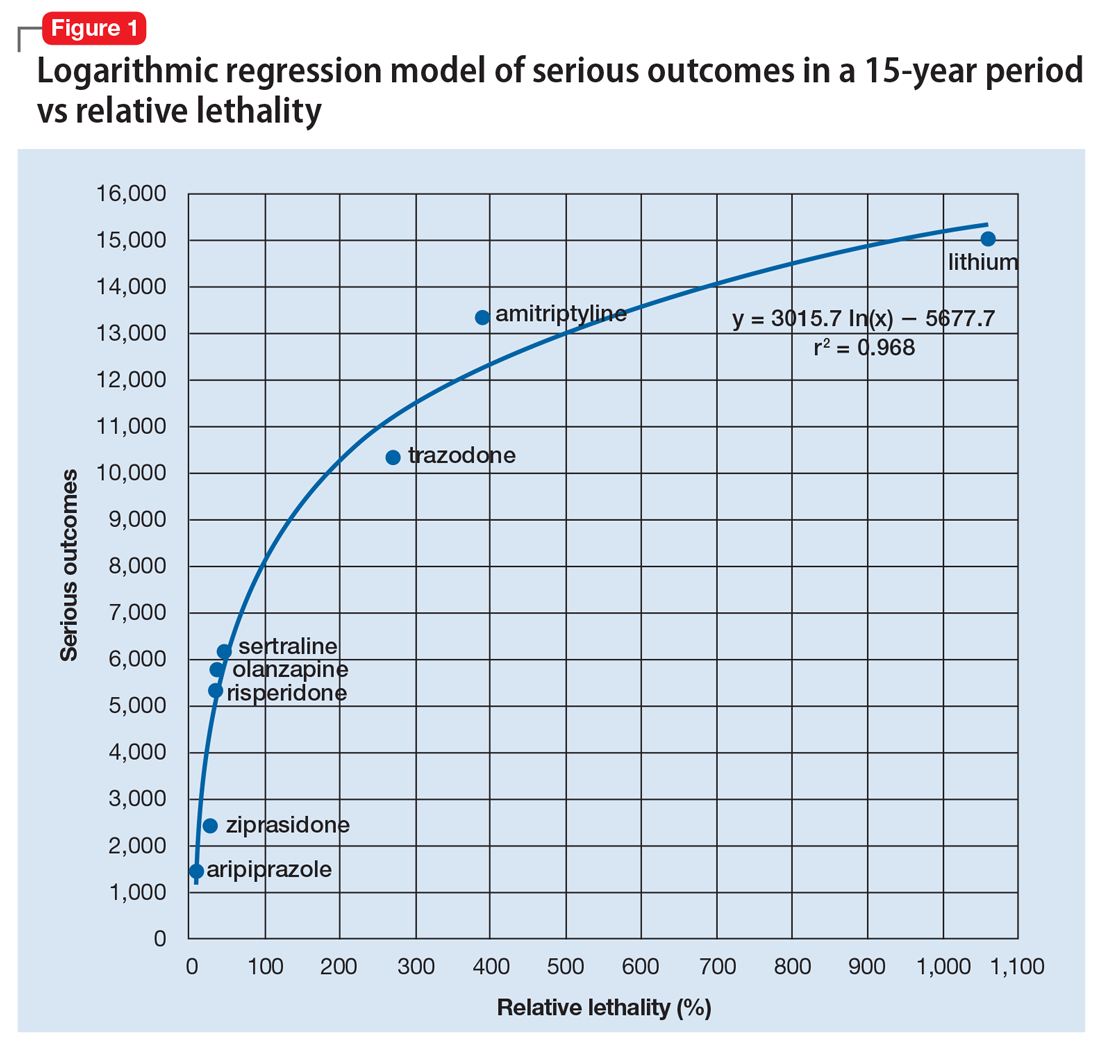
The model predicts that medications with a lower RL will have fewer serious outcomes, including mortality. The coefficient of determination r2 = 0.968, which indicates that 97% of the variation in serious outcomes is attributed to variation in RL, and 3% may be due to other factors, such as the poor quality of U.S. poison control data. This is a very significant correlation, and the causality is self-evident.
Continued to: The distribution of bad outcomes in the model was...