Algorithms for Prediction of Clinical Deterioration on the General Wards: A Scoping Review





OBJECTIVE: The primary objective of this scoping review was to identify and describe state-of-the-art models that use vital sign monitoring to predict clinical deterioration on the general ward. The secondary objective was to identify facilitators, barriers, and effects of implementing these models.
DATA SOURCES: PubMed, Embase, and CINAHL databases until November 2020.
STUDY SELECTION: We selected studies that compared vital signs–based automated real-time predictive algorithms to current track-and-trace protocols in regard to the outcome of clinical deterioration in a general ward population.
DATA EXTRACTION: Study characteristics, predictive characteristics and barriers, facilitators, and effects.
RESULTS: We identified 1741 publications, 21 of which were included in our review. Two of the these were clinical trials, 2 were prospective observational studies, and the remaining 17 were retrospective studies. All of the studies focused on hospitalized adult patients. The reported area under the receiver operating characteristic curves ranged between 0.65 and 0.95 for the outcome of clinical deterioration. Positive predictive value and sensitivity ranged between 0.223 and 0.773 and from 7.2% to 84.0%, respectively. Input variables differed widely, and predicted endpoints were inconsistently defined. We identified 57 facilitators and 48 barriers to the implementation of these models. We found 68 reported effects, 57 of which were positive.
CONCLUSION: Predictive algorithms can detect clinical deterioration on the general ward earlier and more accurately than conventional protocols, which in one recent study led to lower mortality. Consensus is needed on input variables, predictive time horizons, and definitions of endpoints to better facilitate comparative research.
RESULTS
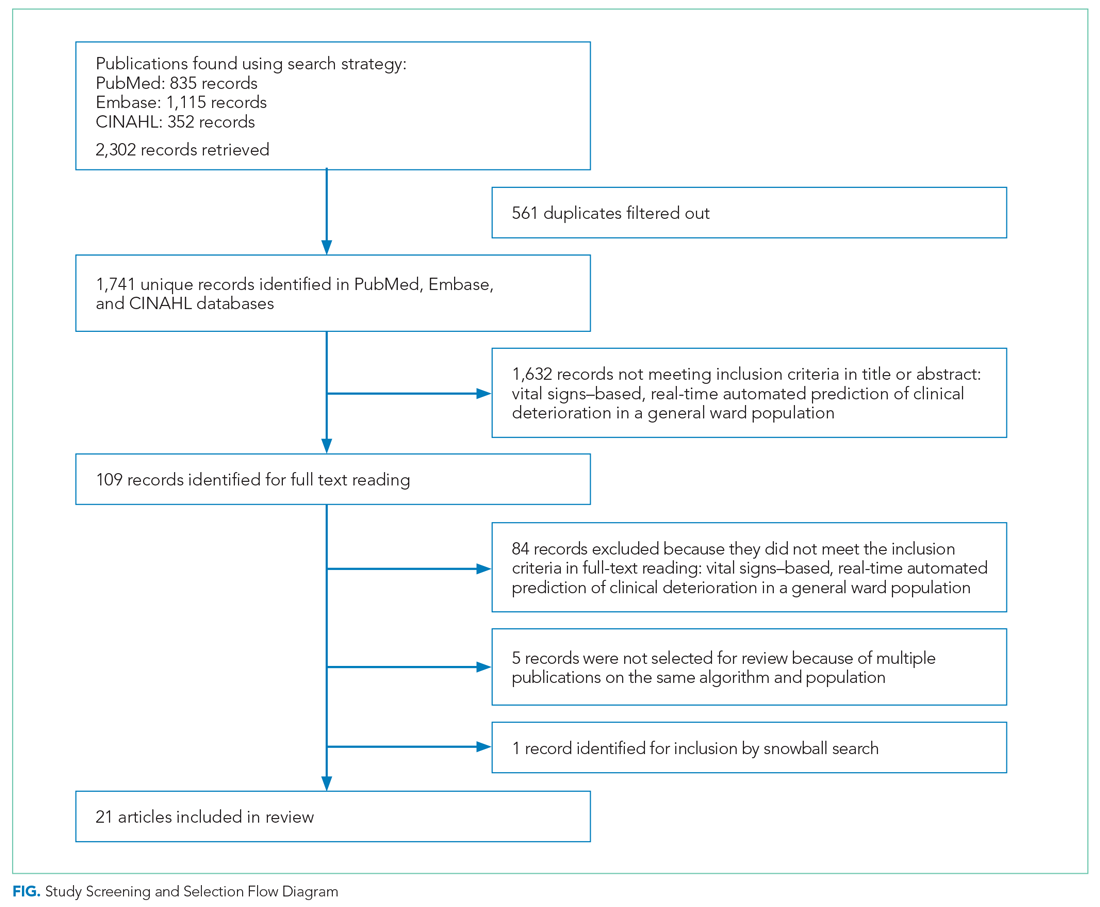
As shown in the Figure, we found 1741 publications, of which we read the full-text of 109. There were 1632 publications that did not meet the inclusion criteria. The publications by Churpek et al,20,21 Bartkiowak et al,22 Edelson et al,23 Escobar et al,24,25 and Kipnis et al26 reported on the same algorithms or databases but had significantly different approaches. For multiple publications using the same algorithm and population, the most recent was named with inclusion of the earlier findings.20,21,27-29 The resulting 21 papers are included in this review.
Descriptive characteristics of the studies are summarized in Table 1. Nineteen of the publications were full papers and two were conference abstracts. Most of the studies (n = 18) were from the United States; there was one study from South Korea,30 one study from Portugal,31 and one study from the United Kingdom.32 In 15 of the studies, there was a strict focus on general or specific wards; 6 studies also included the ICU and/or emergency departments.
Two of the studies were clinical trials, 2 were prospective observational studies, and 17 were retrospective studies. Five studies reported on an active predictive model during admission. Of these, 3 reported that the model was clinically implemented, using the predictions in their clinical workflow. None of the implemented studies used AI.
All input variables are presented in Appendix Table 1.
The non-AI algorithm prediction horizons ranged from 4 to 24 hours, with a median of 24 hours (interquartile range [IQR], 12-24 hours). The AI algorithms ranged from 2 to 48 hours and had a median horizon of 14 hours (IQR, 12-24 hours).
We found three studies reporting patient outcomes. The most recent of these was a large multicenter implementation study by Escobar et al25 that included an extensive follow-up response. This study reported a significantly decreased 30-day mortality in the intervention cohort. A smaller randomized controlled trial reported no significant differences in patient outcomes with earlier warning alarms.27 A third study reported more appropriate rapid response team deployment and decreased mortality in a subgroup analysis.35
Effects, Facilitators, and Barriers
As shown in the Appendix Figure and further detailed in Table 3, the described effects were predominantly positive—57 positive effects vs 11 negative effects. These positive effects sorted primarily into the outcome and process domains.
