Methodolgical Progress Note: Handling Missing Data in Clinical Research





© 2019 Society of Hospital Medicine
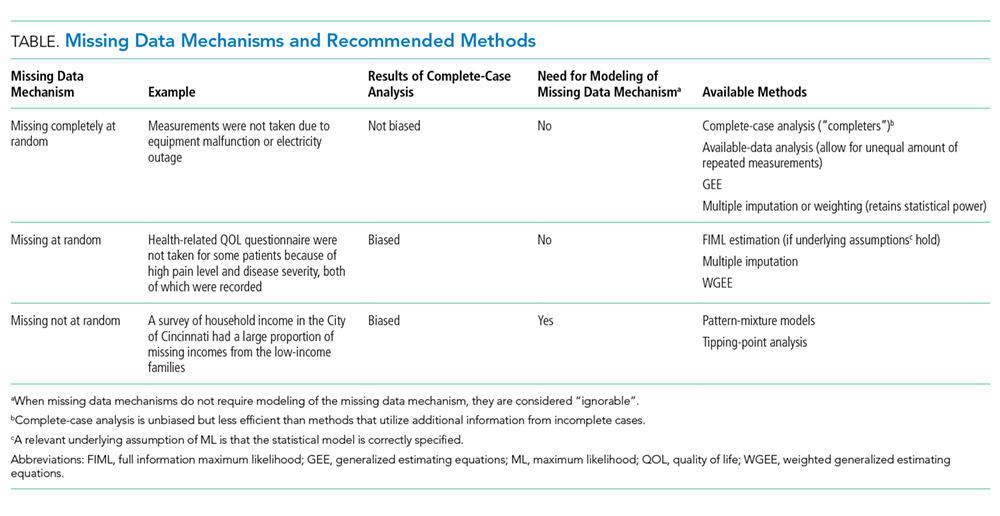
Missing Data Mechanisms
The missing data mechanism relates to the underlying reasons for missing values and the relationships between variables with and without missing data. In general, missing data can be either random or nonrandom with distinctions in randomness made by three types: (1) data missing completely at random (MCAR); (2) data missing at random (MAR); and (3) data missing not at random (MNAR).6 As with the missing data pattern, understanding the missing data mechanism can aid in selecting an appropriate approach to handling the missing data.
Data are MCAR if the missingness does not depend on any study variables, meaning that all subjects are equally likely to be missing certain data elements. When the data are MCAR, those with missing values can be viewed as a simple random sample from the complete (but never actually observed) data and can be dropped from analysis without causing bias in the results. If the values of some diagnostic tests were missing for some patients due to equipment malfunction or electricity outage, for example, then the missingness may be considered MCAR.
Data are MAR if the missingness depends on the observed characteristics but not the unobserved characteristics, meaning that the relationships observed in the data can be used to predict the occurrence of missing values. Because the “randomness” of MAR is conditional on observed characteristics, which distinguishes it from the “completely at random” type of MCAR, dropping or omitting those cases with missing values from the analysis may lead to biased results.7 In a study of quality of life (QOL) for patients with mild to moderate traumatic brain injury, if health-related QOL questions were not answered by some patients with high pain levels (even though the pain levels were recorded), the missingness of QOL may be considered as MAR. This is due to the fact that within subjects grouped by the observed characteristic of pain (that is, conditional on similar levels of pain) the missingness of QOL is the result of chance and does not depend on the values (observed or unobserved) of QOL. It follows then, that once grouped into a high (or low) pain stratum, if QOL is considered MAR, then, whether or not it is observed, is random.
Data are considered MNAR if their missingness depends on characteristics that are not observed and cannot be fully explained by the observed characteristics. Systematic differences between missing and nonmissing data exist for data that is MNAR. For example, if a survey of household income had an increased probability of missing incomes from the low-income families then the data would be considered as MNAR.
Randomness in the missing data mechanism may be ignored without affecting the inference in some circumstances.8 Both MCAR and MAR can be considered as “ignorable” in the sense that a proper method (eg, multiple imputation) may recover the missing information without modeling (ie, accounting for) the random process of the missing data mechanism (Table).9 In contrast, the MNAR mechanism requires a method that takes into account the missing data mechanism in order to make inferences about the complete (and partially unobserved) data; or in other words, a model for the missing data mechanism cannot be ignored. It is for this reason that the MNAR mechanism is often called “nonignorable”. Nonignorable missing data present a challenge to researchers because the mechanism underlying the missingness must be included in the analysis. Yet researchers rarely know what the missingness mechanism is, and the data needed to validate any putative mechanism is, in fact, missing. In cases when more than one variable is subject to missingness, researchers need to assess the missingness mechanism for each variable and tailor their approach to the specific missing data problems.9